Vineet Gandhi
 |
(lastname)(firstname)@gmail.com +33 476615529 Inria Rhone Alpes
|
I recently completed my PhD (yay!) in Imagine team at INRIA Rhone Alpes, under the supervision of Dr. Remi Ronfard. I was funded by the CIBLE scholarship by Region Rhone Alpes under the framework of Scenoptique project. Prior to this, I completed my Masters with prestigious Erasmus Mundus scholarship under CIMET consortium in May 2011. I did my master thesis under the supervision of Dr. Radu Horaud and Dr. Jan Cech in the Perception team at INRIA Rhone Alpes. I obtained my Bachelor of Technology degree from Indian Institute of Information Technology, Jabalpur, India. For my bachelor thesis I worked with Prof. Challa S Sastry (IIT Hyderabad) and Prof. Amit Ray (IIT Kanpur).
My main research interests are in the areas of visual detection, tracking and recognition, computational photography/videography/cinematography, mathematics of signal and image processing, and multiple sensor fusion for depth estimation.
| CV | [pdf] [LinkedIn] |
| Current/Past Affiliations |  |
 |
News
| Dec 18, 2014 | Defended my PhD! Hurray! | |
| Sept 8, 2014 | "Multi-Clip Video Editing from a Single Viewpoint" accepted to CVMP 2014 | |
| Feb 25, 2013 | "Detecting and naming actors in movies using generative appearance models" accepted to CVPR 2013 | |
| Sept 28, 2012 | "Recorded the dress rehearsal of the play Death of a salesman at theater Celestin in Lyon | |
| Mar 14, 2012 | "Recorded the dress rehearsal of the play Lorenzaccio at theater Celestin in Lyon | |
| Jan 1, 2012 | "High-Resolution Depth Maps Based on TOF-Stereo Fusion" accepted to ICRA 2012 |
Publications
List of publications @ Google Scholar
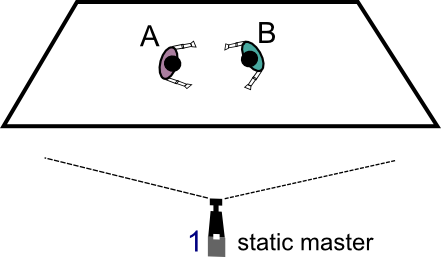 |
Gandhi Vineet Automatic Rush Generation with Application to Theatre Performances PhD dissertation [abstract] [pdf] [BibTex] Professional quality videos of live staged performances are created by recording them from different appropriate viewpoints. These are then edited together to portray an eloquent story replete with the ability to draw out the intended emotion from the viewers. Creating such competent videos typically requires a team of skilled camera operators to capture the scene from multiple viewpoints. In this thesis, we explore an alternative approach where we automatically compute camera movements in post-production using specially designed computer vision methods. A high resolution static camera replaces the plural camera crew and their efficient cam- era movements are then simulated by virtually panning - tilting - zooming within the original recordings. We show that multiple virtual cameras can be simulated by choosing different trajectories of cropping windows inside the original recording. One of the key novelties of this work is an optimization framework for computing the virtual camera trajectories using the in- formation extracted from the original video based on computer vision techniques. The actors present on stage are considered as the most important elements of the scene. For the task of localizing and naming actors, we introduce generative models for learning view independent person and costume specific detectors from a set of labeled examples. We explain how to learn the models from a small number of labeled keyframes or video tracks, and how to detect novel appearances of the actors in a maximum likelihood framework. We demonstrate that such actor specific models can accurately localize actors despite changes in view point and occlusions, and significantly improve the detection recall rates over generic detectors. The thesis then proposes an offline algorithm for tracking objects and actors in long video sequences using these actor specific models. Detections are first performed to independently select candidate locations of the actor/object in each frame of the video. The candidate detections are then combined into smooth trajectories by minimizing a cost function accounting for false detections and occlusions. Using the actor tracks, we then describe a method for automatically generating multiple clips suitable for video editing by simulating pan-tilt-zoom camera movements within the frame of a single static camera. Our method requires only minimal user input to define the subject matter of each sub-clip. The composition of each sub-clip is automatically computed in a novel convex optimization framework. Our approach encodes several common cinematographic practices into a single convex cost function minimization problem, resulting in aesthetically-pleasing sub-clips which can easily be edited together using off-the-shelf multiclip video editing software. The proposed methods have been tested and validated on a challenging corpus of theatre recordings. They open the way to novel applications of computer vision methods for cost- effective video production of live performances including, but not restricted to, theatre, music and opera. @inproceedings{gandhi-dissertation-2014,
title = {{Automatic Rush Generation with Application to Theatre Performances}},
author = {Gandhi, Vineet},
booktitle = {{PhD dissertation}},
year = {2014},
}
|
|
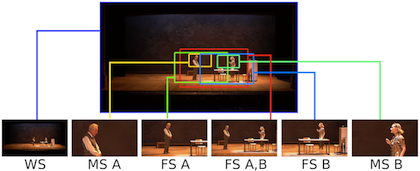 |
Gandhi Vineet, Ronfard Remi, Gleicher Michael Multi-Clip Video Editing from a Single Viewpoint European Conference on Visual Media Production (CVMP) 2014 [abstract] [paper] [Presentation slides] [www] [BibTex] We propose a framework for automatically generating multiple clips suitable for video editing by simulating pan-tilt-zoom camera movements within the frame of a single static camera. Assuming important actors and objects can be localized using computer vision techniques, our method requires only minimal user input to define the subject matter of each sub-clip. The composition of each sub-clip is automatically computed in a novel L1-norm optimization framework. Our approach encodes several common cinematographic practices into a single convex cost function minimization problem, resulting in aesthetically-pleasing sub-clips which can easily be edited together using off-the-shelf multi-clip video editing software. We demonstrate our approach on five video sequences of a live theatre performance by generating multiple synchronized sub-clips for each sequence. @inproceedings{gandhi-cvmp-2014,
title = {{Multi-Clip Video Editing from a Single Viewpoint}},
author = {Gandhi, Vineet and Ronfard, Remi and Gleicher, Michael},
booktitle = {{European Conference on Visual Media Production (CVMP)}},
year = {2014},
}
|
|
 |
Gandhi Vineet, Ronfard Remi Detecting and naming actors in movies using generative appearance models Computer Vision and Pattern Recognition (CVPR) 2013 [abstract] [paper] [CVPR 2013 Poster (1.8mb)] [www] [BibTex] We introduce a generative model for learning person and costume specific detectors from labeled examples. We demonstrate the model on the task of localizing and nam- ing actors in long video sequences. More specifically, the actor’s head and shoulders are each represented as a con- stellation of optional color regions. Detection can proceed despite changes in view-point and partial occlusions. We explain how to learn the models from a small number of la- beled keyframes or video tracks, and how to detect novel appearances of the actors in a maximum likelihood frame- work. We present results on a challenging movie example, with 81% recall in actor detection (coverage) and 89% pre- cision in actor identification (naming). @inproceedings{gandhi-cvpr-2013,
title = {{Detecting and Naming Actors in Movies using Generative Appearance Models}},
author = {Gandhi, Vineet and Ronfard, Remi},
booktitle = {{CVPR}},
year = {2013},
}
|
|
 |
Gandhi Vineet, Cech Jan and Horaud Radu High-Resolution Depth Maps Based on TOF-Stereo Fusion IEEE International Conference on Robotics and Automation (ICRA) 2012 [abstract] [paper] [www] [BibTex] The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial ''seeds'' are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU. @inproceedings{gandhi-icra-2012,
AUTHOR = {Gandhi, Vineet and Cech, Jan and Horaud, Radu},
TITLE = {{High-Resolution Depth Maps Based on TOF-Stereo Fusion}},
BOOKTITLE = {{ICRA}},
YEAR = {2012}}
|
|
 |
Ronfard Remi, Gandhi Vineet and Boiron Laurent The Prose Storyboard Language: A Tool for Annotating and Directing Movies Workshop on Intelligent Cinematography and Editing part of Foundations of Digital Games (FDG) 2013 [abstract] [paper] [www] [BibTex] The prose storyboard language is a formal language for describing movies shot by shot, where each shot is described with a unique sentence. The language uses a simple syntax and limited vocabulary borrowed from working practices in traditional movie-making, and is intended to be readable both by machines and humans. The language is designed to serve as a high-level user interface for intelligent cinematography and editing systems. @inproceedings{ronfard-wiced-2013,
title = {{The Prose Storyboard Language: A Tool for Annotating and Directing Movies}},
author = {Ronfard, Remi and Gandhi, Vineet and Boiron, Laurent},
booktitle = {{2nd Workshop on Intelligent Cinematography and Editing part of Foundations of Digital Games - FDG 2013}},
year = {2013},
}
|
Code and Data
Coming soon
Miscellaneous
Coming soon
Last updated: April 2014